Background¶
This section introduces the notation used in this benchmark library, and provides a brief overview of graph embedding methods. In-depth analysis of graph embedding theory we refer the reader to here.
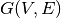 denotes a weighted graph where
denotes a weighted graph where 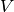 is the set of vertices and
is the set of vertices and 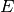 is the set of edges. We represent
is the set of edges. We represent  as the adjacency matrix of
as the adjacency matrix of 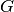 , where
, where 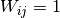 represents the presence of an edge between
represents the presence of an edge between 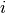 and
and 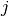 . A graph embedding is a mapping
. A graph embedding is a mapping 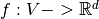 , where
, where 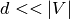 and the function
and the function 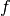 preserves some proximity measure defined on graph . It aims to map similar nodes close to each other. Function when applied on the graph yields an embedding
preserves some proximity measure defined on graph . It aims to map similar nodes close to each other. Function when applied on the graph yields an embedding 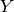 .
.
In this benchmark library, we evaluate four state-of-the-art graph embedding methods on a set of real graphs denoted by 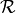 and synthetic graphs denoted by
and synthetic graphs denoted by 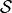 . To analyze the performance of methods, we categorize the graphs into a set of domains
. To analyze the performance of methods, we categorize the graphs into a set of domains 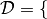 Social, Economic, Biology, Technological:math:rbrace. The set of graphs in a domain
Social, Economic, Biology, Technological:math:rbrace. The set of graphs in a domain 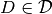 is represented as
is represented as 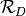 . We use multiple evaluation metrics on graph embedding methods to draw insights into each approach. We denote this set of metrics as
. We use multiple evaluation metrics on graph embedding methods to draw insights into each approach. We denote this set of metrics as 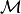 . The notations are summarized as follows:.
. The notations are summarized as follows:.
- : Graphical representation of the data
- : Set of edges in the graph
- : Adjacency matrix of the graph,
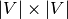
- : Embedding function
- : Set of synthetic graphs
- : Set of real graphs in domain
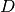
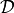 : Set of domains
: Set of domains- : Set of evaluation metrics
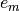 : Evaluation function for metric
: Evaluation function for metric 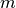
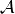 : Set of graph and embedding attributes
: Set of graph and embedding attributes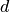 : Number of embedding dimensions
: Number of embedding dimensions- : Embedding of the graph,
Graph Embedding Methods¶
Graph embedding methods embed graph vertices into a low-dimensional space. The goal of graph embedding is to preserve certain properties of the original graph such as distance between nodes and neighborhood structure. Based upon the function used for embedding the graph, existing methods can be classified into three categories: factorization based, random walk based and deep learning based.
Factorization based approaches¶
Factorization based approaches apply factorization on graph related matrices to obtain the node representation. Graph matrices such as the adjacency matrix, Laplacian matrix, and Katz similarity matrix contain information about node connectivity and the graph’s structure. Other matrix factorization approaches use the eigenvectors from spectral decomposition of a graph matrix as node embeddings. For example, to preserve locality, LLE uses eigenvectors corresponding to eigenvalues from second smallest to 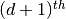 smallest from the sparse matrix
smallest from the sparse matrix  . It assumes that the embedding of each node is a linear weighted combination of the neighbor’s embeddings. Laplacian Eigenmaps take the first eigenvectors with the smallest eigenvalues of the normalized Laplacian
. It assumes that the embedding of each node is a linear weighted combination of the neighbor’s embeddings. Laplacian Eigenmaps take the first eigenvectors with the smallest eigenvalues of the normalized Laplacian 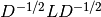 . Both LLE and Laplacian Eigenmaps were designed to preserve the local geometric relationships of the data. Another type of matrix factorization methods learn node embeddings under different optimization functions in order to preserve certain properties. Structural Preserving Embedding builds upon Laplacian Eigenmaps to recover the original graph. Cauchy Graph Embedding uses a quadratic distance formula in the objective function to emphasize similar nodes instead of dissimilar nodes. Graph Factorization uses an approximation function to factorize the adjacency matrix in a more scalable manner. GraRep and HOPE were invented to keep the high order proximity in the graph. Factorization based approaches have been widely used in practical applications due to their scalability. The methods are also easy to implement and can yield quick insights into the data set.
. Both LLE and Laplacian Eigenmaps were designed to preserve the local geometric relationships of the data. Another type of matrix factorization methods learn node embeddings under different optimization functions in order to preserve certain properties. Structural Preserving Embedding builds upon Laplacian Eigenmaps to recover the original graph. Cauchy Graph Embedding uses a quadratic distance formula in the objective function to emphasize similar nodes instead of dissimilar nodes. Graph Factorization uses an approximation function to factorize the adjacency matrix in a more scalable manner. GraRep and HOPE were invented to keep the high order proximity in the graph. Factorization based approaches have been widely used in practical applications due to their scalability. The methods are also easy to implement and can yield quick insights into the data set.
Random walk approaches¶
Random walk based algorithms are more flexible than factorization methods to explore the local neighborhood of a node for high-order proximity preservation. DeepWalk and Node2vec aim to learn a low-dimensional feature representation for nodes through a stream of random walks. These random walks explore the nodes’ variant neighborhoods. Thus, random walk based methods are much more scalable for large graphs and they generate informative embeddings. Although very similar in nature, DeepWalk simulates uniform random walks and Node2vec employs search-biased random walks, which enables embedding to capture the community or structural equivalence via different bias settings. LINE combines two phases for embedding feature learning: one phase uses a breadth-first search (BFS) traversal across first-order neighbors, and the second phase focuses on sampling nodes from second-order neighbors. HARP improves DeepWalk and Node2vec by creating a hierarchy for nodes and using the embedding of the coarsened graph as a better initialization in the original graph. Walklets extended Deepwalk by using multiple skip lengths in random walking. Random walk based approaches tend to be more computationally expensive than factorization based approaches but can capture complex properties and longer dependencies between nodes.
Neural network approaches¶
The third category of graph embedding approaches is based on neural networks. Deep neural networks based approaches capture highly non-linear network structure in graphs, which is neglected by factorization based and random walk based methods. One type of deep learning based methods such as SDNE uses a deep autoencoder to provide non-linear functions to preserve the first and second order proximities jointly. Similarly, DNGR applies random surfing on input graph before a stacked denoising autoencoder and makes the embedding robust to noise in graphs. Another genre of methods use Graph Neural Networks(GNNs) and Graph Convolutional Networks (GCNs) (bruna2013spectral, henaff2015deep, li2015gated, hamilton2017inductive) to aggregate the neighbors embeddings and features via convolutional operators, including spatial or spectral filters. GCNs learn embeddings in a semi-supervised manner and have shown great improvement and scalability on large graphs compared to other methods. SEAL learns a wide range of link prediction heuristics from extracted local enclosing subgraphs with GNN. DIFFPOOL employs a differentiable graph pooling module on GNNs to learn hierarchical embeddings of graphs. Variational Graph Auto Encoders (VGAE) utilizes a GCN as encoder and inner product as decoder, which provides embedding with higher quality than autoencoders. Deep neural network based algorithms like SDNE and DNGR can be computational costly since they require the global information such as adjacency matrix for each node as input. GCNs based methods are more scalable and flexible to characterize global and local neighbours through variant convolutional and pooling layers.