Baseline Graph Embedding Algorithms¶
Adamic Adar¶
-
class
gemben.embedding.aa.AdamicAdar(*hyper_dict, **kwargs)[source]¶ -
Adamic Adar is based on the intuition that common neighbors with very large neighbourhoods are less significant than common neighbors with small neighborhoods when predicting a connection between two nodes. Formally, it is defined as the sum of the inverse logarithmic degree centrality of the neighbours shared by the two nodes.
- Parameters
Examples
>>> from gemben.embedding.aa import AdamicAdar >>> edge_f = 'data/karate.edgelist' >>> G = graph_util.loadGraphFromEdgeListTxt(edge_f, directed=False) >>> G = G.to_directed() >>> res_pre = 'results/testKarate' >>> graph_util.print_graph_stats(G) >>> t1 = time() >>> embedding = AdamicAdar(4, 0.01) >>> embedding.learn_embedding(graph=G, edge_f=None, is_weighted=True, no_python=True) >>> print('Adamic Adar: Training time: %f' % (time() - t1))
-
get_edge_weight(self, i, j)[source]¶ Compute the weight for edge between node i and node j
- Parameters
j (i,) – two node id in the graph for embedding
- Returns
A single number represent the weight of edge between node i and node j
-
get_method_name(self)[source]¶ Returns the name for the embedding method
- Returns
The name of embedding
-
get_method_summary(self)[source]¶ Returns the summary for the embedding include method name and paramater setting
- Returns
A summary string of the method
Static Graph Embedding¶
Common Neighbors¶
-
class
gemben.embedding.cn.CommonNeighbors(*hyper_dict, **kwargs)[source]¶ -
Common Neighbors defines the similarity between nodes as the number of common neighbors between them.
- Parameters
Examples
>>> from gemben.embedding.cn import CommonNeighbors >>> edge_f = 'data/karate.edgelist' >>> G = graph_util.loadGraphFromEdgeListTxt(edge_f, directed=False) >>> G = G.to_directed() >>> res_pre = 'results/testKarate' >>> graph_util.print_graph_stats(G) >>> t1 = time() >>> embedding = CommonNeighbors(4, 0.01) >>> embedding.learn_embedding(graph=G, edge_f=None, is_weighted=True, no_python=True) >>> print('Common Neighbors: Training time: %f' % (time() - t1))
-
get_edge_weight(self, i, j)[source]¶ Compute the weight for edge between node i and node j
- Parameters
j (i,) – two node id in the graph for embedding
- Returns
A single number represent the weight of edge between node i and node j
-
get_method_name(self)[source]¶ Returns the name for the embedding method
- Returns
The name of embedding
-
get_method_summary(self)[source]¶ Returns the summary for the embedding include method name and paramater setting
- Returns
A summary string of the method
Graph Convolution Network¶
Graph Factorization¶
-
class
gemben.embedding.gf.GraphFactorization(*hyper_dict, **kwargs)[source]¶ -
Graph Factorization factorizes the adjacency matrix with regularization.
- Parameters
Examples
>>> from gemben.embedding.gf import GraphFactorization >>> edge_f = 'data/karate.edgelist' >>> G = graph_util.loadGraphFromEdgeListTxt(edge_f, directed=False) >>> G = G.to_directed() >>> res_pre = 'results/testKarate' >>> graph_util.print_graph_stats(G) >>> t1 = time() >>> embedding = GraphFactorization(2, 100000, 1 * 10**-4, 1.0) >>> embedding.learn_embedding(graph=G, edge_f=None, is_weighted=True, no_python=True) >>> print ('Graph Factorization:Training time: %f' % (time() - t1)) >>> viz.plot_embedding2D(embedding.get_embedding(), di_graph=G, node_colors=None) >>> plt.show()
-
get_edge_weight(self, i, j)[source]¶ Compute the weight for edge between node i and node j
- Parameters
j (i,) – two node id in the graph for embedding
- Returns
A single number represent the weight of edge between node i and node j
-
get_method_name(self)[source]¶ Returns the name for the embedding method
- Returns
The name of embedding
-
get_method_summary(self)[source]¶ Returns the summary for the embedding include method name and paramater setting
- Returns
A summary string of the method
HOPE¶
-
class
gemben.embedding.hope.HOPE(*hyper_dict, **kwargs)[source]¶ Higher Order Proximity Preserving.
Higher Order Proximity factorizes the higher order similarity matrix between nodes using generalized singular value decomposition.
- Parameters
Examples
>>> from gemben.embedding.hope import HOPE >>> edge_f = 'data/karate.edgelist' >>> G = graph_util.loadGraphFromEdgeListTxt(edge_f, directed=False) >>> G = G.to_directed() >>> res_pre = 'results/testKarate' >>> graph_util.print_graph_stats(G) >>> t1 = time() >>> embedding = HOPE(4, 0.01) >>> embedding.learn_embedding(graph=G, edge_f=None, is_weighted=True, no_python=True) >>> print('HOPE:Training time: %f' % (time() - t1)) >>> viz.plot_embedding2D(embedding.get_embedding()[:, :2], di_graph=G, node_colors=None) >>> plt.show()
-
get_edge_weight(self, i, j)[source]¶ Compute the weight for edge between node i and node j
- Parameters
j (i,) – two node id in the graph for embedding
- Returns
A single number represent the weight of edge between node i and node j
-
get_method_name(self)[source]¶ Returns the name for the embedding method
- Returns
The name of embedding
-
get_method_summary(self)[source]¶ Returns the summary for the embedding include method name and paramater setting
- Returns
A summary string of the method
Jaccard Coefficient¶
-
class
gemben.embedding.jc.JaccardCoefficient(*hyper_dict, **kwargs)[source]¶ -
Jaccard Coefficient measures the probability that two nodes
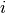 and
and 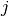 have a connection to node
have a connection to node 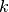 ,
for a randomly selected node $k$ from the neighbors of and .
,
for a randomly selected node $k$ from the neighbors of and .- Parameters
Examples
>>> from gemben.embedding.jc import JaccardCoefficient >>> edge_f = 'data/karate.edgelist' >>> G = graph_util.loadGraphFromEdgeListTxt(edge_f, directed=False) >>> G = G.to_directed() >>> res_pre = 'results/testKarate' >>> graph_util.print_graph_stats(G) >>> t1 = time() >>> embedding = JaccardCoefficient(4, 0.01) >>> embedding.learn_embedding(graph=G, edge_f=None, is_weighted=True, no_python=True) >>> print('Adamic Adar:Training time: %f' % (time() - t1))
-
get_edge_weight(self, i, j)[source]¶ Compute the weight for edge between node i and node j
- Parameters
j (i,) – two node id in the graph for embedding
- Returns
A single number represent the weight of edge between node i and node j
-
get_method_name(self)[source]¶ Returns the name for the embedding method
- Returns
The name of embedding
-
get_method_summary(self)[source]¶ Returns the summary for the embedding include method name and paramater setting
- Returns
A summary string of the method
Laplacian Eigenmaps¶
-
class
gemben.embedding.lap.LaplacianEigenmaps(*hyper_dict, **kwargs)[source]¶ -
LaplacianEigenmaps penalizes the weighted square of distance between neighbors. This is equivalent to factorizing the normalized Laplacian matrix.
- Parameters
Examples
>>> from gemben.embedding.lap import LaplacianEigenmaps >>> edge_f = 'data/karate.edgelist' >>> G = graph_util.loadGraphFromEdgeListTxt(edge_f, directed=False) >>> G = G.to_directed() >>> res_pre = 'results/testKarate' >>> graph_util.print_graph_stats(G) >>> t1 = time() >>> embedding = LaplacianEigenmaps(2) >>> embedding.learn_embedding(graph=G, edge_f=None, is_weighted=True, no_python=True) >>> print('Laplacian Eigenmaps:Training time: %f' % (time() - t1)) >>> viz.plot_embedding2D(embedding.get_embedding(), di_graph=G, node_colors=None) >>> plt.show()
-
get_edge_weight(self, i, j)[source]¶ Compute the weight for edge between node i and node j
- Parameters
j (i,) – two node id in the graph for embedding
- Returns
A single number represent the weight of edge between node i and node j
-
get_method_name(self)[source]¶ Returns the name for the embedding method
- Returns
The name of embedding
-
get_method_summary(self)[source]¶ Returns the summary for the embedding include method name and paramater setting
- Returns
A summary string of the method
Locally Linear Embedding¶
-
class
gemben.embedding.lle.LocallyLinearEmbedding(*hyper_dict, **kwargs)[source]¶ -
Locally Linear Embedding uses
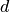 eigenvectors corresponding to
eigenvalues from second smallest to
eigenvectors corresponding to
eigenvalues from second smallest to 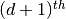 smallest
from the sparse matrix
smallest
from the sparse matrix  . It assumes
that the embedding of each node is a linear weighted combination
of the neighbor’s embeddings.
. It assumes
that the embedding of each node is a linear weighted combination
of the neighbor’s embeddings.- Parameters
Examples
>>> from gemben.embedding.lle import LocallyLinearEmbedding >>> edge_f = 'data/karate.edgelist' >>> G = graph_util.loadGraphFromEdgeListTxt(edge_f, directed=False) >>> G = G.to_directed() >>> res_pre = 'results/testKarate' >>> graph_util.print_graph_stats(G) >>> t1 = time() >>> embedding = LocallyLinearEmbedding(2) >>> embedding.learn_embedding(graph=G, edge_f=None, is_weighted=True, no_python=True) >>> print('Graph Factorization:Training time: %f' % (time() - t1)) >>> viz.plot_embedding2D(embedding.get_embedding(), di_graph=G, node_colors=None) >>> plt.show()
-
get_edge_weight(self, i, j)[source]¶ Compute the weight for edge between node i and node j
- Parameters
j (i,) – two node id in the graph for embedding
- Returns
A single number represent the weight of edge between node i and node j
-
get_method_name(self)[source]¶ Returns the name for the embedding method
- Returns
The name of embedding
-
get_method_summary(self)[source]¶ Returns the summary for the embedding include method name and paramater setting
- Returns
A summary string of the method
node2vec¶
-
class
gemben.embedding.node2vec.node2vec(*hyper_dict, **kwargs)[source]¶ -
Node2Vec aim to learn a low-dimensional feature representation for nodes through a stream of random walks. These random walks explore the nodes’ variant neighborhoods. Thus, random walk based methods are much more scalable for large graphs and they generate informative embeddings.
- Parameters
Examples
>>> from gemben.embedding.node2vec import node2vec >>> edge_f = 'data/karate.edgelist' >>> G = graph_util.loadGraphFromEdgeListTxt(edge_f, directed=False) >>> G = G.to_directed() >>> res_pre = 'results/testKarate' >>> graph_util.print_graph_stats(G) >>> t1 = time() >>> embedding = node2vec(2, 1, 80, 10, 10, 1, 1) >>> embedding.learn_embedding(graph=G, edge_f=None, is_weighted=True, no_python=True) >>> print('node2vec:Training time: %f' % (time() - t1)) >>> viz.plot_embedding2D(embedding.get_embedding(), di_graph=G, node_colors=None) >>> plt.show()
-
get_edge_weight(self, i, j)[source]¶ Compute the weight for edge between node i and node j
- Parameters
j (i,) – two node id in the graph for embedding
- Returns
A single number represent the weight of edge between node i and node j
-
get_method_name(self)[source]¶ Returns the name for the embedding method
- Returns
The name of embedding
-
get_method_summary(self)[source]¶ Returns the summary for the embedding include method name and paramater setting
- Returns
A summary string of the method
Preferential Attachment¶
-
class
gemben.embedding.pa.PreferentialAttachment(*hyper_dict, **kwargs)[source]¶ -
Preferential Attachment is based on the assumption that the connection to a node is proportional to its degree. It defines the similarity between the nodes as the product of their degrees.
- Parameters
Examples
>>> from gemben.embedding.pa import PreferentialAttachment >>> edge_f = 'data/karate.edgelist' >>> G = graph_util.loadGraphFromEdgeListTxt(edge_f, directed=False) >>> G = G.to_directed() >>> res_pre = 'results/testKarate' >>> graph_util.print_graph_stats(G) >>> t1 = time() >>> embedding = PreferentialAttachment(2) >>> embedding.learn_embedding(graph=G, edge_f=None, is_weighted=True, no_python=True) >>> print('PreferentialAttachment:Training time: %f' % (time() - t1)) >>> viz.plot_embedding2D(embedding.get_embedding(), di_graph=G, node_colors=None) >>> plt.show()
-
get_edge_weight(self, i, j)[source]¶ Compute the weight for edge between node i and node j
- Parameters
j (i,) – two node id in the graph for embedding
- Returns
A single number represent the weight of edge between node i and node j
-
get_method_name(self)[source]¶ Returns the name for the embedding method
- Returns
The name of embedding
-
get_method_summary(self)[source]¶ Returns the summary for the embedding include method name and paramater setting
- Returns
A summary string of the method
Random Embedding¶
-
class
gemben.embedding.rand.RandomEmb(*hyper_dict, **kwargs)[source]¶ Random Embedding.
It generates the random embedding for the graph.
- Parameters
Examples
>>> from gemben.embedding.rand import RandomEmb >>> edge_f = 'data/karate.edgelist' >>> G = graph_util.loadGraphFromEdgeListTxt(edge_f, directed=False) >>> G = G.to_directed() >>> res_pre = 'results/testKarate' >>> graph_util.print_graph_stats(G) >>> t1 = time() >>> embedding = PreferentialAttachment(2) >>> embedding.learn_embedding(graph=G, edge_f=None, is_weighted=True, no_python=True) >>> print('PreferentialAttachment:Training time: %f' % (time() - t1)) >>> viz.plot_embedding2D(embedding.get_embedding(), di_graph=G, node_colors=None) >>> plt.show()
-
get_edge_weight(self, i, j)[source]¶ Compute the weight for edge between node i and node j
- Parameters
j (i,) – two node id in the graph for embedding
- Returns
A single number represent the weight of edge between node i and node j
-
get_method_name(self)[source]¶ Returns the name for the embedding method
- Returns
The name of embedding
-
get_method_summary(self)[source]¶ Returns the summary for the embedding include method name and paramater setting
- Returns
A summary string of the method
SDNE¶
-
class
gemben.embedding.sdne.SDNE(*hyper_dict, **kwargs)[source]¶ SDNE.
SDNE uses a deep autoencoder to provide non-linear functions to preserve the first and second order proximities jointly.
- Parameters
Examples
>>> from gemben.embedding.sdne import SDNE >>> file_prefix = "gemben/data/sbm/graph.gpickle" >>> G = nx.read_gpickle(file_prefix) >>> node_colors = pickle.load( open('gemben/data/sbm/node_labels.pickle', 'rb') ) >>> embedding = SDNE(d=128, beta=5, alpha=1e-5, nu1=1e-6, nu2=1e-6, K=3, n_units=[500, 300, ], n_iter=30, xeta=1e-3, n_batch=500, modelfile=['gemben/intermediate/enc_model.json', 'gemben/intermediate/dec_model.json'], weightfile=['gemben/intermediate/enc_weights.hdf5', 'gemben/intermediate/dec_weights.hdf5']) >>> G_X = nx.to_numpy_matrix(G) >>> embedding.learn_embedding(G) >>> G_X_hat = embedding.get_reconstructed_adj() >>> rec_norm = np.linalg.norm(G_X - G_X_hat) >>> print(rec_norm) >>> node_colors_arr = [None] * node_colors.shape[0] >>> for idx in range(node_colors.shape[0]): node_colors_arr[idx] = np.where(node_colors[idx, :].toarray() == 1)[1][0] >>> viz.plot_embedding2D(G_X, di_graph=G, node_colors=node_colors_arr) >>> plt.savefig('sdne_sbm_g_x.pdf', bbox_inches='tight')
-
get_edge_weight(self, i, j, embed=None, filesuffix=None)[source]¶ Compute the weight for edge between node i and node j
- Parameters
j (i,) – two node id in the graph for embedding
- Returns
A single number represent the weight of edge between node i and node j
-
get_embedding(self, filesuffix=None)[source]¶ Returns the learnt embedding
- Returns
A numpy array of size #nodes * d
-
get_method_name(self)[source]¶ Returns the name for the embedding method
- Returns
The name of embedding
-
get_method_summary(self)[source]¶ Returns the summary for the embedding include method name and paramater setting
- Returns
A summary string of the method
Variational Auto-Encoder¶
gemben utility function¶
Static Graph Embedding utils¶
Visualization¶
-
gemben.evaluation.visualize_embedding.expVis(X, res_pre, m_summ, node_labels=None, di_graph=None)[source]¶ Function used to visualize the experiment.
- Parameters
X (Vetor) – Embedding values of the nodes.
res_pre (Str) – Prefix to be used to save the result.
m_summ (Str) – String to denote the name of the summary file.
node_pos (Vector) – High dimensional embedding values of each nodes.
node_labels (List) – List consisting of node labels.
di_graph (Object) – network graph object of the original network.
-
gemben.evaluation.visualize_embedding.plot_embedding2D(node_pos, node_colors=None, di_graph=None)[source]¶ Function to plot the embedding in two dimension.
- Parameters
node_pos (Vector) – High dimensional embedding values of each nodes.
node_colors (List) – List consisting of node colors.
di_graph (Object) – network graph object of the original network.
Embeding Utility Function¶
Bayesian Optimizer¶
-
class
gemben.utils.bayesian_opt.BayesianOpt(*args, **kwargs)[source]¶ bayesian global optimization with Gaussian Process
Bayesian optimization is a module to perform hyper-paramter tuning. It can be utilized to find the best hyper-parameter with fewer iterations.
Examples
>>> from bayes_opt import BayesianOptimization >>> def black_box_function(x, y): return x+y >>> pbounds = {'x': (2, 4), 'y': (-3, 3)} >>> optimizer = BayesianOptimization(f=black_box_function, pbounds=pbounds, verbose=2, # verbose = 1 prints only when a maximum is observed, verbose = 0 is silent random_state=1,) >>> optimizer.maximize(init_points=2, n_iter=3,) >>> print(optimizer.max)
Methods
optimization_func(self, \*\*hyp_space)The main method to be optimized
optimize(self[, random_state, verbose, …])Function to perform the actual optimization.
search_space(self, hyp_range)Function to define the search space
Evaluation Utility Function¶
-
class
gemben.utils.bayesian_opt.BayesianOpt(*args, **kwargs)[source] bayesian global optimization with Gaussian Process
Bayesian optimization is a module to perform hyper-paramter tuning. It can be utilized to find the best hyper-parameter with fewer iterations.
Examples
>>> from bayes_opt import BayesianOptimization >>> def black_box_function(x, y): return x+y >>> pbounds = {'x': (2, 4), 'y': (-3, 3)} >>> optimizer = BayesianOptimization(f=black_box_function, pbounds=pbounds, verbose=2, # verbose = 1 prints only when a maximum is observed, verbose = 0 is silent random_state=1,) >>> optimizer.maximize(init_points=2, n_iter=3,) >>> print(optimizer.max)
Methods
optimization_func(self, \*\*hyp_space)The main method to be optimized
optimize(self[, random_state, verbose, …])Function to perform the actual optimization.
search_space(self, hyp_range)Function to define the search space
-
optimization_func(self, **hyp_space)[source] The main method to be optimized
-
optimize(self, random_state=5, verbose=2, init_points=10, n_iter=5, acq='poi')[source] Function to perform the actual optimization.
-
search_space(self, hyp_range)[source] Function to define the search space
-
Graph Generation Functions¶
-
gemben.utils.graph_gens.barabasi_albert_graph(N, deg, dia, dim, domain)[source]¶ Return random graph using Barabási-Albert preferential attachment model.
- Parameters
:param : return: Graph Object
- Returns
Best graph, beast average degree and best diameter.
- Return type
Object
-
gemben.utils.graph_gens.barbell_graph(m1, m2)[source]¶ Function to generate barbell graph.
A n-barbell graph is the simple graph obtained by connecting two copies of a complete graph K_n by a bridge.
Return the Barbell Graph: two complete graphs connected by a path.
For m1 > 1 and m2 >= 0.
Two identical complete graphs K_{m1} form the left and right bells, and are connected by a path P_{m2}.
- The 2*m1+m2 nodes are numbered
0,…,m1-1 for the left barbell, m1,…,m1+m2-1 for the path, and m1+m2,…,2*m1+m2-1 for the right barbell.
-
gemben.utils.graph_gens.binary_community_graph(N, k, maxk, mu)[source]¶ Retruns a binary community graph.
-
gemben.utils.graph_gens.duplication_divergence_graph(N, deg, dia, dim, domain)[source]¶ Returns an undirected graph using the duplication-divergence model.
A graph of
nnodes is created by duplicating the initial nodes and retaining edges incident to the original nodes with a retention probabilityp.Parameters of the graph: n (int) – The desired number of nodes in the graph. p (float) – The probability for retaining the edge of the replicated node.
-
gemben.utils.graph_gens.hyperbolic_graph(N, deg, dia, dim, domain)[source]¶ The Hyperbolic Generator distributes points in hyperbolic space and adds edges between points with a probability depending on their distance. The resulting graphs have a power-law degree distribution, small diameter and high clustering coefficient. For a temperature of 0, the model resembles a unit-disk model in hyperbolic space.
Parameters of the graph: N = Num of nodes k = Average degree gamma = Target exponent in Power Law Distribution
-
gemben.utils.graph_gens.lfr_benchmark_graph(N, deg, dia, dim, domain)[source]¶ Returns the LFR benchmark graph for testing community-finding algorithms.
Parameters of the graph: n (int) – Number of nodes in the created graph. tau1 (float) – Power law exponent for the degree distribution of the created graph. This value must be strictly greater than one. tau2 (float) – Power law exponent for the community size distribution in the created graph. This value must be strictly greater than one. mu (float) – Fraction of intra-community edges incident to each node. This value must be in the interval [0, 1]. average_degree (float) – Desired average degree of nodes in the created graph. This value must be in the interval [0, n]. Exactly one of this and min_degree must be specified, otherwise a NetworkXError is raised.
-
gemben.utils.graph_gens.plot_hist(title, data)[source]¶ Function to truncate the given floating point values.
-
gemben.utils.graph_gens.powerlaw_cluster_graph(N, deg, dia, dim, domain)[source]¶ Holme and Kim algorithm for growing graphs with powerlaw degree distribution and approximate average clustering.
The average clustering has a hard time getting above a certain cutoff that depends on
m. This cutoff is often quite low. The transitivity (fraction of triangles to possible triangles) seems to decrease with network size.It is essentially the Barabási–Albert (BA) growth model with an extra step that each random edge is followed by a chance of making an edge to one of its neighbors too (and thus a triangle).
This algorithm improves on BA in the sense that it enables a higher average clustering to be attained if desired.
It seems possible to have a disconnected graph with this algorithm since the initial
mnodes may not be all linked to a new node on the first iteration like the BA model.Parameters of the graph: n (int) – the number of nodes m (int) – the number of random edges to add for each new node p (float,) – Probability of adding a triangle after adding a random edge Formula for m: (m^2)- (Nm)/2 + avg_deg * (N/2) = 0 => From this equation we need to find m : p : Does not vary the average degree or diameter so much. : Higher value of p may cause average degree to overshoot intended average_deg so we give the control of average degree to parameter m: by setting a lower value of p: 0.1
-
gemben.utils.graph_gens.r_mat_graph(N, deg, dia, dim, domain)[source]¶ Generates static R-MAT graphs.
R-MAT (recursive matrix) graphs are random graphs with n=2^scale nodes and m=n*edgeFactor edges. More details at http://www.graph500.org or in the original paper: Deepayan Chakrabarti, Yiping Zhan, Christos Faloutsos: R-MAT: A Recursive Model for Graph Mining.
-
gemben.utils.graph_gens.random_geometric_graph(N, deg, dia, dim, domain)[source]¶ Return the random geometric graph in the unit cube.
The random geometric graph model places n nodes uniformly at random in the unit cube Two nodes u,v are connected with an edge if d(u,v)<=r where d is the Euclidean distance and r is a radius threshold.
Average Degree is given by formula: Avg_Deg = (pi*(r^2)*num_nodes)/(l^2) Formula for r: avg_deg * l where l can be considered a constant where its square can be approximated to 1.04 [ength of square] Empirically Found
-
gemben.utils.graph_gens.stochastic_block_model(N, deg, dia, dim, domain)[source]¶ Returns a stochastic block model graph.
This model partitions the nodes in blocks of arbitrary sizes, and places edges between pairs of nodes independently, with a probability that depends on the blocks.
- Parameters
N – Number of Nodes
p – Element (r,s) gives the density of edges going from the nodes of group r to nodes of group s. p must match the number of groups (len(sizes) == len(p)), and it must be symmetric if the graph is undirected.
- Formula for p: Through Empirical Studies - p = 0.001 * Deg gives perfect result for Num_of_Nodes = 1024
But if N >1024: scaler = N/1024 : then p = (0.001*deg)/scaler And if N < 1024 : Scaler = 1024/N : then p = (0.001*deg)*scaler and if N == 1024: p = (0.001*deg)
-
gemben.utils.graph_gens.stochastic_kronecker_graph(N, deg, dia, dim, domain)[source]¶ Generates stochastic kronecker graph.
The stochastic Kronecker graph model introduced by Leskovec etal. is a random graph with vertex setZn2, where two verticesuandvare connected with probability αu·vγ(1−u)·(1−v)βn−u·v−(1−u)·(1−v) in-dependently of the presence or absence of any other edge, for fixedparameters 0< α,β,γ <1. They have shown empirically that the de-gree sequence resembles a power law degree distribution. In this paperwe show that the stochastic Kronecker graph a.a.s. does not feature apower law degree distribution for any parameters 0< α,β,γ <1.
Parameters of the graph: degree_seq
-
gemben.utils.graph_gens.truncate(f, n)[source]¶ Function to truncate the given floating point values.
-
gemben.utils.graph_gens.watts_strogatz_graph(N, deg, dia, dim, domain)[source]¶ Return a Watts-Strogatz small-world graph.
First create a ring over n nodes. Then each node in the ring is connected with its k nearest neighbors (k-1 neighbors if k is odd). Then shortcuts are created by replacing some edges as follows: for each edge u-v in the underlying “n-ring with k nearest neighbors” with probability p replace it with a new edge u-w with uniformly random choice of existing node w.
Parameters of the graph: n (int) – The number of nodes k (int) – Each node is joined with its k nearest neighbors in a ring topology. p (float) – The probability of rewiring each edge
Average Degree is solely decided by k Diameter depends on the value of p
-
gemben.utils.graph_gens.waxman_graph(N, deg, dia, dim, domain)[source]¶ Return a Waxman random graph.
The Waxman random graph models place n nodes uniformly at random in a rectangular domain. Two nodes u,v are connected with an edge with probability
Parameters of the graph: n (int or iterable) – Number of nodes or iterable of nodes
beta (float) – Model parameter
alpha (float) – Model parameter
Average Degree is given by formula: k where P = beta * exp(-d/alpha*L) alpha = (gamma((k/2)+1) * (beta^k))/((n-1)*(pi^(k/2))*gamma(k)) where beta is chosen randomly to satisfy the average degree criterion So we fix the parameter beta = 0.1, and we know the default value of d/L is in range: 0.25 to 0.3 (Empiricially calculated) so we only tweak alpha to get the required avg deg.
Graph Utility Functions¶
-
gemben.utils.graph_util.addNodeAnomalies(di_graphs, p, k)[source]¶ Function to add anomalous edges in the graph.
-
gemben.utils.graph_util.randwalk_DiGraph_to_adj(di_graph, node_frac=0.1, n_walks_per_node=5, len_rw=2)[source]¶ Function to perform a randomwalk on directed graph and return the adjacency list.
-
gemben.utils.graph_util.sample_graph(di_graph, n_sampled_nodes=None)[source]¶ Function to sample the graph.
-
gemben.utils.graph_util.sample_graph_rw(di_graph, n_sampled_nodes=None, random_res_p=0.01, verbose=False)[source]¶ Function to return the sampled graph.
Kronecker Graph Generator¶
-
gemben.utils.kronecker_generator.convert(something)[source]¶ Function to convert the numpy array to networkx graph.
Kronecker Matrix Initializer¶
-
class
gemben.utils.kronecker_init_matrix.InitMatrix(numNodes, W=None)[source]¶ Class module to initialize the kronechker graph.
Methods
addEdge
addSelfEdges
getMtxSum
getNumNodes
getValue
make
makeFromNetworkxGraph
makeStochasticAB
makeStochasticABFromNetworkxGraph
makeStochasticCustom
setNumNodes
setValue
lrf graph generator¶
-
gemben.utils.lrf_gen.average_degree(dmax, dmin, gamma)[source]¶ Function to calculate average degree.
Plotting Utility Function¶
-
gemben.utils.plot_util.get_node_color(node_community)[source]¶ Function to get the node colors for the communities.
-
gemben.utils.plot_util.plot(x_s, y_s, fig_n, x_lab, y_lab, file_save_path, title, legendLabels=None, show=False)[source]¶ Function to plot the graph with respective embeddings.
-
gemben.utils.plot_util.plotExpRes(res_pre, methods, exp, d_arr, save_fig_pre, n_rounds, plot_d, plot_ratio=0.8, samp_scheme='u_rand', K=1024)[source]¶ Function to plot experiment results for maps.
-
gemben.utils.plot_util.plot_F1(res_pre, res_suffix, exp_type, m_names_f, m_names, d_arr, n_rounds, save_fig_name, K=1024, plot_d=False)[source]¶ Function to plot the F1-score.
-
gemben.utils.plot_util.plot_hyp(hyp_keys, exp_param, meth, data, s_sch='u_rand')[source]¶ Function to explore the hyperparameters.
-
gemben.utils.plot_util.plot_hyp_all(hyp_keys, exp_param, meth, data_sets, s_sch='u_rand')[source]¶ Function to plot all the hyper-parameter results.
-
gemben.utils.plot_util.plot_hyp_data(hyp_keys, exp_param, meths, data, s_sch='u_rand', dim=2)[source]¶ Function to plot the result of hyperparameter exploration.
-
gemben.utils.plot_util.plot_hyp_data2(hyp_keys, exp_param, meths, data, s_sch='u_rand', dim=2)[source]¶ Function to plot the result of hyper-parameter exploration.
-
gemben.utils.plot_util.plot_p_at_k(res_pre, res_suffix, exp_type, m_names_f, m_names, d_arr, n_rounds, save_fig_name, K=1024, plot_d=False, plot_ratio=0.8, s_sch='u_rand')[source]¶ Function to plot precision at k.
Evaluation Module¶
Graph Reconstruction¶
-
gemben.evaluation.evaluate_graph_reconstruction.evaluateStaticGraphReconstruction(digraph, graph_embedding, X_stat, node_l=None, file_suffix=None, sample_ratio_e=None, is_undirected=True, is_weighted=False)[source]¶ This function evaluates the graph reconstruction accuracy of the embedding algorithms.
- Parameters
digraph (Object) – directed networkx graph object.
graph_embedding (object) – Object of the embedding algorithm class defined in gemben/embedding.
X_stat (Vector) – Embedding of the the nodes of the graph.
node_l (Int) – Number of nodes in the graph.
file_suffix (Str) – The name of the algorithm and dataset used to save the embedding.
sample_ratio_e (Float) – The ratio used to sample the original graph for evaluation purpose.
is_undirected (bool) – Boolean flag to denote whether the graph is directed or not.
is_weighted (bool) – Boolean flag to denote whether the edges of the graph is weighted.
- Returns
Consiting of Mean average precision precision curve, errors and error baselines.
- Return type
Numpy Array
-
gemben.evaluation.evaluate_graph_reconstruction.expGR(digraph, graph_embedding, X, n_sampled_nodes_l, rounds, res_pre, m_summ, K=10000, is_undirected=True, sampling_scheme='u_rand')[source]¶ This function is used to experiment graph reconstruction.
- Parameters
digraph (Object) – directed networkx graph object.
graph_embedding (object) – Object of the embedding algorithm class defined in gemben/embedding.
X (Vector) – Embedding of the the nodes of the graph.
n_sampled_node_l (Int) – Number of nodes in the graph.
rounds (Int) – The number of times the graph reconstruction is performed.
res_pre (Str) – Prefix to be used to save the result.
m_summ (Str) – String to denote the name of the summary file.
K (Int) – The maximum value to be use to get the precision curves.
sampling_scheme (Str) – Sampling schme used to sample nodes to be reconstructed.
is_undirected (bool) – Boolean flag to denote whether the graph is directed or not.
- Returns
Consisting of Mean average precision.
- Return type
Numpy Array
Link Prediction¶
-
gemben.evaluation.evaluate_link_prediction.evaluateStaticLinkPrediction(train_digraph, test_digraph, graph_embedding, X, node_l=None, sample_ratio_e=None, is_undirected=True, store_predictions=1)[source]¶ This function evaluates the static link prediction accuracy of the embedding algorithms.
- Parameters
train_digraph (Object) – directed networkx graph object used for training the algorithm.
test_digraph (Object) – directed networkx graph object to be used for testing the algorithm.
graph_embedding (object) – Object of the embedding algorithm class defined in gemben/embedding.
X (Vector) – Embedding of the the nodes of the graph.
node_l (Int) – Number of nodes in the graph.
sample_ratio_e (Float) – The ratio used to sample the original graph for evaluation purpose.
is_undirected (bool) – Boolean flag to denote whether the graph is directed or not.
store_prediction (Int) – Stores the predicted values.
- Returns
Consiting of Mean average precision and the precision curve values.
- Return type
Numpy Array
-
gemben.evaluation.evaluate_link_prediction.expLP(digraph, graph_embedding, n_sample_nodes_l, rounds, res_pre, m_summ, train_ratio=0.8, no_python=True, K=32768, is_undirected=True, sampling_scheme='u_rand')[source]¶ This function is used to experiment link prediction.
- Parameters
digraph (Object) – directed networkx graph object.
graph_embedding (object) – Object of the embedding algorithm class defined in gemben/embedding.
n_sampled_node_l (Int) – Number of nodes in the graph.
rounds (Int) – The number of times the graph reconstruction is performed.
res_pre (Str) – Prefix to be used to save the result.
train_ratio (Float) – The split used for dividing the traing and testing data.
no_python (Bool) – Flag to denote if python is used.
m_summ (Str) – String to denote the name of the summary file.
K (Int) – The maximum value to be use to get the precision curves.
sampling_scheme (Str) – Sampling schme used to sample nodes to be reconstructed.
is_undirected (bool) – Boolean flag to denote whether the graph is directed or not.
- Returns
Consisting of Mean average precision.
- Return type
Numpy Array
-
gemben.evaluation.evaluate_link_prediction.expLPT(digraph, graph_embedding, res_pre, m_summ, K=100000, is_undirected=True)[source]¶ This function is used to experiment graph reconstruction for temporally varying graphs.
- Parameters
digraph (Object) – directed networkx graph object.
graph_embedding (object) – Object of the embedding algorithm class defined in gemben/embedding.
res_pre (Str) – Prefix to be used to save the result.
m_summ (Str) – String to denote the name of the summary file.
K (Int) – The maximum value to be use to get the precision curves.
is_undirected (bool) – Boolean flag to denote whether the graph is directed or not.
Node Classification¶
-
class
gemben.evaluation.evaluate_node_classification.TopKRanker(estimator, n_jobs=None)[source]¶ Class to get top K ranks.
- Attributes
- coef_
- intercept_
multilabel_Whether this is a multilabel classifier
- n_classes_
Methods
decision_function(self, X)Returns the distance of each sample from the decision boundary for each class.
fit(self, X, y)Fit underlying estimators.
get_params(self[, deep])Get parameters for this estimator.
partial_fit(self, X, y[, classes])Partially fit underlying estimators
predict(self, X, top_k_list)This function returns the prediction for top k node labels.
predict_proba(self, X)Probability estimates.
score(self, X, y[, sample_weight])Returns the mean accuracy on the given test data and labels.
set_params(self, \*\*params)Set the parameters of this estimator.
-
gemben.evaluation.evaluate_node_classification.evaluateNodeClassification(X, Y, test_ratio)[source]¶ This function is used to evaluate node classification.
- Parameters
X (Vector) – Embedding values of the nodes.
Y (Int) – Labels of the nodes.
test_ratio (Float) – Ratio to split the training and testing nodes.
- Returns
Micro and macro accuracy scores.
- Return type
Numpy Array
-
gemben.evaluation.evaluate_node_classification.expNC(X, Y, test_ratio_arr, rounds, res_pre, m_summ)[source]¶ This function is used to experiment node classification.
- Parameters
X (vector) – Embedding values of the nodes.
Y (Int) – Labels of the nodes.
rounds (Int) – The number of times the graph reconstruction is performed.
res_pre (Str) – Prefix to be used to save the result.
test_ratio_arr (Float) – The split used for dividing the traing and testing data.
m_summ (Str) – String to denote the name of the summary file.
- Returns
Average accuracy.
- Return type
Numpy Array
Evaluation Metrics¶
-
gemben.evaluation.metrics.computeMAP(predicted_edge_list, true_digraph, max_k=-1)[source]¶ This function computers the Mean average precision.
- Parameters
predicted_edge_list (Array) – Consists of predicted edge list for each node.
true_digraph (object) – True network graph object consists of the original nodes and edges.
max_k (Int) – Maximum number of edges to be considered for computing the precsion.
- Returns
MAP values.
- Return type
Array
-
gemben.evaluation.metrics.computePrecisionCurve(predicted_edge_list, true_digraph, max_k=-1)[source]¶ This function computers the precision curves.
- Parameters
predicted_edge_list (Array) – Consists of predicted edge list for each node.
true_digraph (object) – True network graph object consists of the original nodes and edges.
max_k (Int) – Maximum number of edges to be considered for computing the precsion.
- Returns
Precision scores and delta factors.
- Return type
Array
Experiment Module¶
Simple Experiments¶
A simple experiment to run the gemben library.
Bayesian Hyperparameter Optimizer¶
Experiment to utilize the bayesian hyperparameter tuning for the algorithms.
Full Experiments with Benchmark¶
Example to run the benchmark across all the baseline embedding algorithms.